Google Photon. Обработка данных со скоростью света*
Photon – масштабируемая, отказоустойчивая и географически распределенная система обработки потоковых данных в режиме реального времени. Система является внутренним продуктом Google и используется в Google Advertising System. Research paper [5], описывающие базовые принципы и архитектуру Photon, был представлен на научной конференции ACM SIGMOD в 2013 году.
В paper [5] заявлено, что пиковая нагрузка на систему может составлять миллионы событий в минуту со средней end-to-end задержкой менее 10 секунд.
* ‘Скорость света’ в заголовке — наглая ложь гипербола.

Photon решает вполне конкретную задачу: необходимо соединить (выполнить операцию join) два непрерывных потока данных в режиме реального времени. Так в упоминаемой уже Google Advertising System один из этих потоков – поток поисковых запросов, другой – поток переходов по рекламным объявлениям.
Photon является географически распределенной системой и автоматически способен обрабатывать случаи деградации инфраструктуры, в т.ч. отказа дата-центра. В геораспределенных системах крайне непросто гарантировать время доставки сообщений (в первую очередь, из-за сетевых задержек), поэтому Photon допускает, что обрабатываемые потоковые данные могут быть не упорядочены по времени.
Используемые сервисы: Google File System, PaxosDB, TrueTime.
Базовые принципы
В [5] объяснение принципов работы Photon идет в следующем контексте: пользователь ввел поисковый запрос (query) в момент времени t1 и перешел по рекламному объявлению (click) в момент времени t2. В этом же контексте, если не задано иного, в этой статье будут объяснены принципы работы Photon.
Принцип объединения потоков (join) взят из мира РСУБД: поток query имеет уникальный идентификатор query_id (условно Primary Key), поток click имеет уникальный идентификатор click_id и включает в себя некоторый query_id (условно Foreign Key). Объединение потоков происходит по query_id.
Следующий важный момент: ситуация, когда один click event посчитан дважды, либо, наоборот, не посчитан, будет вести, соответственно, либо к судебным искам со стороны рекламодателей, либо к упущенным выгодам со стороны Google. Отсюда, крайне важно обеспечить at-most-once семантику обработки событий.
Другое требование – обеспечить near-exact семантику, т.е. чтобы большая часть событий была посчитана в режиме близкому real-time. События, не посчитанные в real-time, все равно должны быть посчитаны — exactly-once семантика.
Кроме того, для экземпляров Photon, работающих в разных дата-центрах, необходимо синхронизированное состояние(точнее только critical state, так как между ДЦ весь state слишком «дорого» реплицировать). Таким синхронизируемымcritical state выбрали event_id (по сути, click_id). Critical state храниться в структуре IdRegistry – in-memory key-value хранилище, построенное на основе PaxosDB.
Последний – PaxosDB – реализует алгоритм Paxos для поддержки отказоустойчивости и согласованности данных.
Взаимодействие с клиентами
Worker-узлы взаимодействуют с IdRegistry по клиент-серверной модели. Архитектурно взаимодействие Worker-узлов с IdRegistry – это сетевое взаимодействие с очередью асинхронных сообщений.
Так клиенты – Worker-узлы — отправляют к IdRegistry только 1) запрос на поиск event_id (если event_id найден, значит он уже был обработан) и 2) запрос на вставку event_id (для случая, если на шаге 1 event_id не был найден). На стороне сервера запросы принимают RPC-обработчики, целью которых поставить запрос в очередь. Из очереди запросы забирает специальный процесс Registry Thread (синглтон), который и выполнит запись в PaxosDB и инициализирует обратный вызов (callback) клиенту.
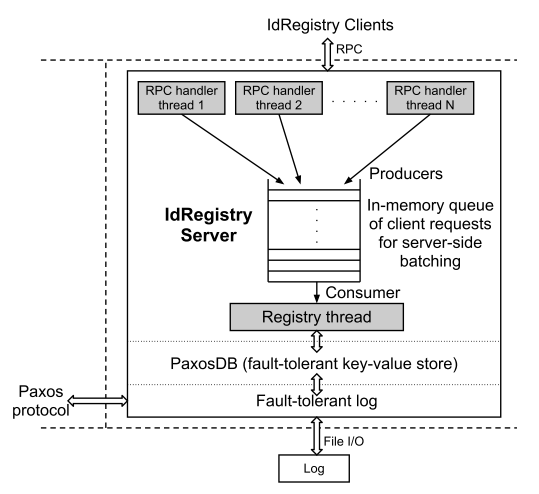
Источник иллюстрации [5, Figure 3]
Масштабируемость
Т.к. реплика IdRegistry происходит между географическим регионами, сетевые задержки между которыми могут достигать 100 мс [5], то это автоматически ограничивает пропускную способность IdRegistry до десяти последовательных транзакций (event_id commits) в секунду, в то время как требование к IdRegistry было равно 10K транзакций в секунду. Но и отказаться от геораспределенности и/или от синхронно репликации critical state с поддержкой решений конфликтов в кворуме также нельзя.
Тогда инженеры Google внедрили еще 2 практики, знакомые многим из мира СУБД:
- пакетная отправка запросов (batching) – «полезная» информация по event_id занимает менее 100 байт; запросы отправляются пакетами на IdRegistry Client. Там они попадают in-memory в очередь, которую разбирает процесс Registry Thread, в обязанности которого входит решение конфликтов, связанные с тем, что в очереди может быть более одного элемента с одинаковым event_id.
- timestamp-based sharding (+ динамический resharding) – все event_id делятся по диапазонам; транзакции по каждому из диапазонов отправляются на определенный IdRegistry.
Пакетная отправка запросов имеет и обратную сторону: кроме смешения семантики (Photon обрабатывает данные real-time, а некоторые его части работают в batching-режиме), batching-сценарий не подойдет для систем c небольшим количеством событий – время сбора полного пакета может занимать существенный интервал времени.
Компоненты
В рамках одного ДЦ выделают следующие компоненты:
- EventStore – обеспечивает эффективный поиск по queries (поток поисковых запросов в поисковой системе);
- Dispatcher – чтение потока кликов по рекламным объявлениям (clicks) и передача (feed) прочитанного Joiner;
- Joiner – stateless RPC-сервер, принимающий запросы от Dispatcher, обрабатывающий их и соединяющий (join) потоки queries и clicks.
Алгоритм добавления записи представлен ниже:
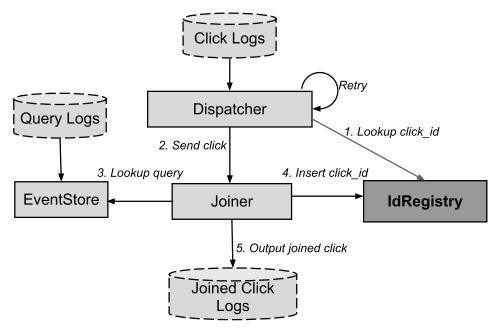
Источник иллюстрации [5, Figure 5]
Взаимодействие между ДЦ:
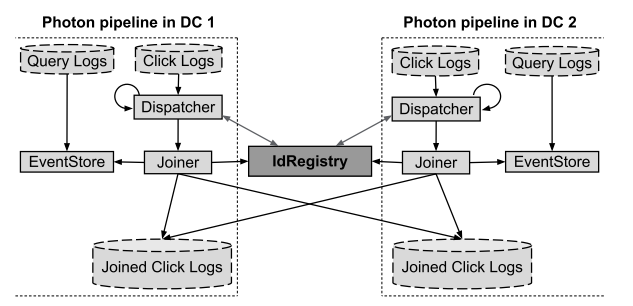
Источник иллюстрации [5, Figure 6]
Алгоритм добавления записи в Joined Click Logs опустим, отметив, что в работы систем с частым сетевым взаимодействием применение retry-политик и асинхронных вызовов является крайне эффективным способом увеличения надежности и масштабируемости системы, соответственно, без усложнения общего алгоритма работы.
Этими же приемами – retry-политик и асинхронных вызов – и воспользовались создатели Photon.
Логика повтора запросов
Dispatcher
Dispatcher – процесс, ответственный за чтение логов кликов — clicks. Эти логи хранятся в GFS и растут во времени непрерывно.
Для того, чтобы эффективно их читать, Dispatcher периодически сканирует директорию с логами и идентифицирует новые файлы и/или измененные, сохраняет состояние каждого файла в локальной GFS-ячейке. Это состояние содержит список файлов и сдвиг от начала файла для данных, которые уже были обработаны. Таким образом при изменении файла, последний вычитывается не с начала, а с того момента, на котором обработка закончилась в прошлое чтение.
Обработка новых данных осуществляется параллельно несколькими процессами, каждый из которых расшаривает свое состояние, что позволяет различным процессам бесконфликтно работать на разными частями одного и того же файла.
Joiner
Joiner – реализация stateless RPC-сервера, принимающего запросы от Dispatcher. Приняв запрос от Dispatcher, Joiner извлекает из него click_id и query_id. После чего по query_id пытается получить информацию из EventStore.
В случае успеха, EventStore возвращает поисковый запрос соответствующий обрабатываемому click.
Далее Joiner удаляет дубликаты (с помощью IdRegistry) и генерирует выходной лог, содержащий объединенные (joined) значения – Joined Click Logs.
Если Dispatcher для обработки отказов использовал retry-логику, то в Joiner инженеры Google добавили еще один прием. Прием работает в случаях, когда Joiner отправил запрос к IdRegistry; последний успешно зарегистрировал click_id, но из-за сетевых проблем, либо по таймауту Joiner так и не получил ответ об успехе от IdRegistry.
Для этого с каждым «commit click_id»-запросом, который Joiner отправляет на IdRegistry, ассоциируется специальный токен. Токен сохраняется в IdRegistry. В случае, если ответ от IdRegistry не был получен, Joiner повторяет запрос с тем же токеном, что и в прошлом запросе, и IdRegistry без труда «понимает», что пришедший запрос уже обрабатывался.
Генерация уникальных токенов / Event_Id
Ясно, что гарантированная уникальность для event_id крайне важное требование для работы Photon. В то же время, алгоритм генерации уникального в рамках нескольких ДЦ значения может занять крайне значительное время и количество CPU-ресурсов.
Инженеры Google нашли элегантное решение: event_id можно уникально идентифицировать используя IP узла (ServerIP), Id процесса (ProcessId) и временную метку (Timestamp) узла, на котором данное событие было сгенерировано.
Как и в случае со Spanner, для минимизации несогласованности временных меток на различных узлах, используется TrueTime API.
EventStore
EventStore – это сервис, принимающий на вход query_id и возвращающий соответствующий query (информацию о поисковом запросе).
В Photon для EventStore имеются 2 реализации:
- CacheEventStore – распределенное [sharding по hash(query_id)] in-memory хранилище, к котором хранится полная информация по query. Таким образом, для ответа на запрос не требуется чтение с диска.
- LogsEventStore — key-value хранилище, где key – query_id, а value – имя log-файла, в котором хранится информацию по соответствующему query, и смещение (byte offset) в этом файле.
Так как Photon работает в режиме близком к реальному времени, то можно с уверенностью гарантировать, что вероятность нахождения query в CacheEventStore (при условии, что в query в него попадают с минимальной задержкой) будет очень высокой, а сам CacheEventStore может хранить события за относительно небольшой промежуток времени.
В researching paper [5] приводится статистика, что только 10% запросов «проходят мимо» in-memory кэша и, соответственно, обрабатываются LogsEventStore.
Результаты
Конфигурация
На момент публикации [5], т.е. в 2013 году, реплики IdRegistry развернуты в 5-ти датацентрах в 3-ех географических регионах (восточное, западное побережье и Mid-West Северной Америки), причем сетевые задержки между регионамипревышают 100 мс. Другие компоненты Photon – Dispatchers, Joiners, etc. – развернуты в 2-ух географических регионах на западном и восточном побережье США.
В каждом из ДЦ количество IdRegistry-шардов превышает сотню, а количество экземпляров процессов Dispatcher и Joiner превышает тысячи.
Производительность
Photon обрабатывает миллиарды joined-событий в день, в том числе, в периоды пиковых нагрузок миллионы событий в минуту. Объем clicks-логов, обрабатываемых за 24 часа, превышает терабайт, а объем суточных query-логов исчисляется десятками терабайт.
90% всех событий обрабатываются (join’ятся в один stream) в первые 7 секунд, после их появления.
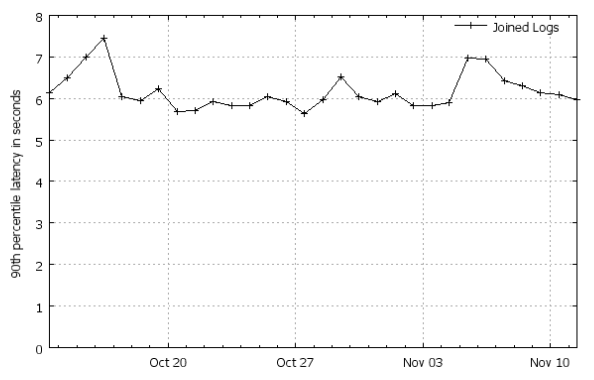
Источник иллюстрации [5, Figure 7]. Больше графиков со статистикой (слайды 24-30).
Простые принципы сложных систем
В разделе «Базовые принципы» я уже упоминал, что Photon является системой с поддержкой exactly-once (at-least-once и at-most-once) и near-exact семантики, т.е. гарантирует, что любое событие, зафиксированное в логах, будет обработано один и только один раз, причем с большой вероятностью в режиме близком к реальному времени.
PaxosDB реализует at-most-once семантику, в то время как retry-политики Dispatcher обеспечивают at-least-once семантику.
Для обработки событий в near-real-time режиме (near-exact семантика) в архитектуре Photon заложены следующие принципы:
- Масштабируемость:
- Обязательный sharding для нереляционных хранилищ;
- Все worker-узлы является stateless.
- Задержка (latency):
- RPC-коммуникации везде, где это возможно;
- Перенос (transfer) данных в RAM везде, где это возможно.
В заключении
В заключении research paper [5], инженеры Google поделились хорошими практиками и своим планами на будущее.
Принципы не новы, но для полноты и законченности статьи, я их перечислю:
- Используйте RPC-коммуникации вместо записи на диск. Запросы, выходящие за физические границы узла, должны выполняться асинхронно, а клиент всегда должен рассчитывать, что не получит ответ по таймауту или из-за сетевых проблем.
- Минимизируйте критическое состояние (critical state) системы, т.к. его, в общем случае, приходится синхронно реплицировать. В идеале в критическое critical state системы должен включать в себя только метаданные системы.
- Sharding – друг масштабируемости :) Но и эту идею инженеры Google улучшили, сделав time-based sharding.
В планах создателей Photon захватить мир уменьшить end-to-end задержки за счет того, что сервера, которые генерируют потоки clicks и queries, будут напрямую отправлять RPC-запросы к Joiner’ам (сейчас Dispatcher «ждет» этих событий). Также планируется Photon «научить» объединять несколько потоков данных (в текущей реализации Photon умеет объединять только 2 потока).
Пожелаем создателям Photon удачи в реализации их планов! И ждем новых research paper!
Список источников**
[5] Rajagopal Ananthanarayanan, Venkatesh Basker, Sumit Das, Ashish Gupta, Haifeng Jiang, Tianhao Qiu, et al. Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams, 2013.
** Полный список источников, используемый для подготовки цикла.
Источник : habrahabr.ru